En enero de 2025 DeepSeek publicó R1 y desató lo que Wall Street bautizó “el DeepSeek moment”: Nvidia perdió USD 600.000 millones de market cap en un día porque una empresa china desconocida había alcanzado capacidad de OpenAI con presupuesto y hardware de un orden de magnitud menor. Quince meses después, DeepSeek está terminando los preparativos para V4 (modelo general de un trillón de parámetros) y R2 (sucesor especializado en razonamiento), y las proyecciones tempranas sugieren un segundo shock — esta vez no por la sorpresa de su existencia, sino por la precisión con la que cierran la brecha contra GPT-5.5, Claude 4.7 y Gemini 3.5 Pro manteniendo un costo 4.5 veces menor.
Este post analiza qué se sabe hasta hoy de DeepSeek V4 y R2, qué muestran los benchmarks proyectados, las decisiones técnicas y geopolíticas detrás (incluyendo el regreso de Nvidia para training R2 después de la apuesta por Huawei), y qué implica concretamente para developers latinoamericanos que ya usamos APIs de IA en producción y miramos costos en dólares.
Qué se sabe (y qué no) hasta mayo 2026
Status oficial al 20 de mayo de 2026: ninguno de los dos modelos está lanzado públicamente. Pero los preparativos son visibles en producción.
- Endpoints
deepseek-v4ydeepseek-r2aparecen intermitentemente en la API de DeepSeek devolviendo 404 — el patrón clásico de modelos en staging. - Filtraciones de papers técnicos en arXiv (más tarde retirados pero archivados) sugieren arquitecturas concretas.
- Anuncios públicos del CEO Liang Wenfeng en eventos chinos confirman que ambos modelos están en testing interno con lanzamiento “antes del segundo semestre de 2026”.
- DeepSeek se asoció con TSMC para producción de chips dedicados, lo que sugiere planes a 2-3 años de inferencia masiva.
La fecha de lanzamiento más probable según las fuentes que estamos siguiendo: V4 entre junio y agosto de 2026, R2 entre agosto y octubre. Esos son los rangos en los que tu equipo debería estar preparado para probarlos.
La arquitectura: trillón de parámetros con Mixture-of-Experts
DeepSeek V4 sigue la línea de V3 (publicado en diciembre de 2024) y la extiende: un modelo Mixture-of-Experts (MoE) con aproximadamente 1 trillón de parámetros totales pero solo 37 mil millones activos por token. Esto le permite tener capacidad de razonamiento de modelo gigante con costos de inferencia de modelo mediano.
Las decisiones técnicas claves filtradas:
- 256 expertos en el FFN, con 8 activados por token (sparsity ratio similar a Mixtral pero con muchos más expertos).
- Multi-head Latent Attention (MLA) mejorado, que reduce el costo de la KV cache en un 80% comparado con attention estándar.
- Context length de 256K tokens nativo, con extension experimental a 1M.
- Training en hardware híbrido: Huawei Ascend 910B para la mayor parte del pretraining (consecuencia del corte de Nvidia H200/H800 a China), pero Nvidia A100 y H100 vía nubes intermediarias para fine-tuning final de R2.
Ese último detalle es geopolíticamente significativo. Después del éxito de R1 entrenado completamente en Huawei, DeepSeek hubiera podido demostrar que China es soberana en IA sin Nvidia. Que para R2 hayan vuelto a chips Nvidia sugiere que la performance final del modelo en razonamiento requería los kernels CUDA optimizados que Huawei todavía no replica adecuadamente. Para Washington es señal de que las sanciones funcionan parcialmente; para Beijing, que la independencia de hardware tomará más tiempo del esperado.
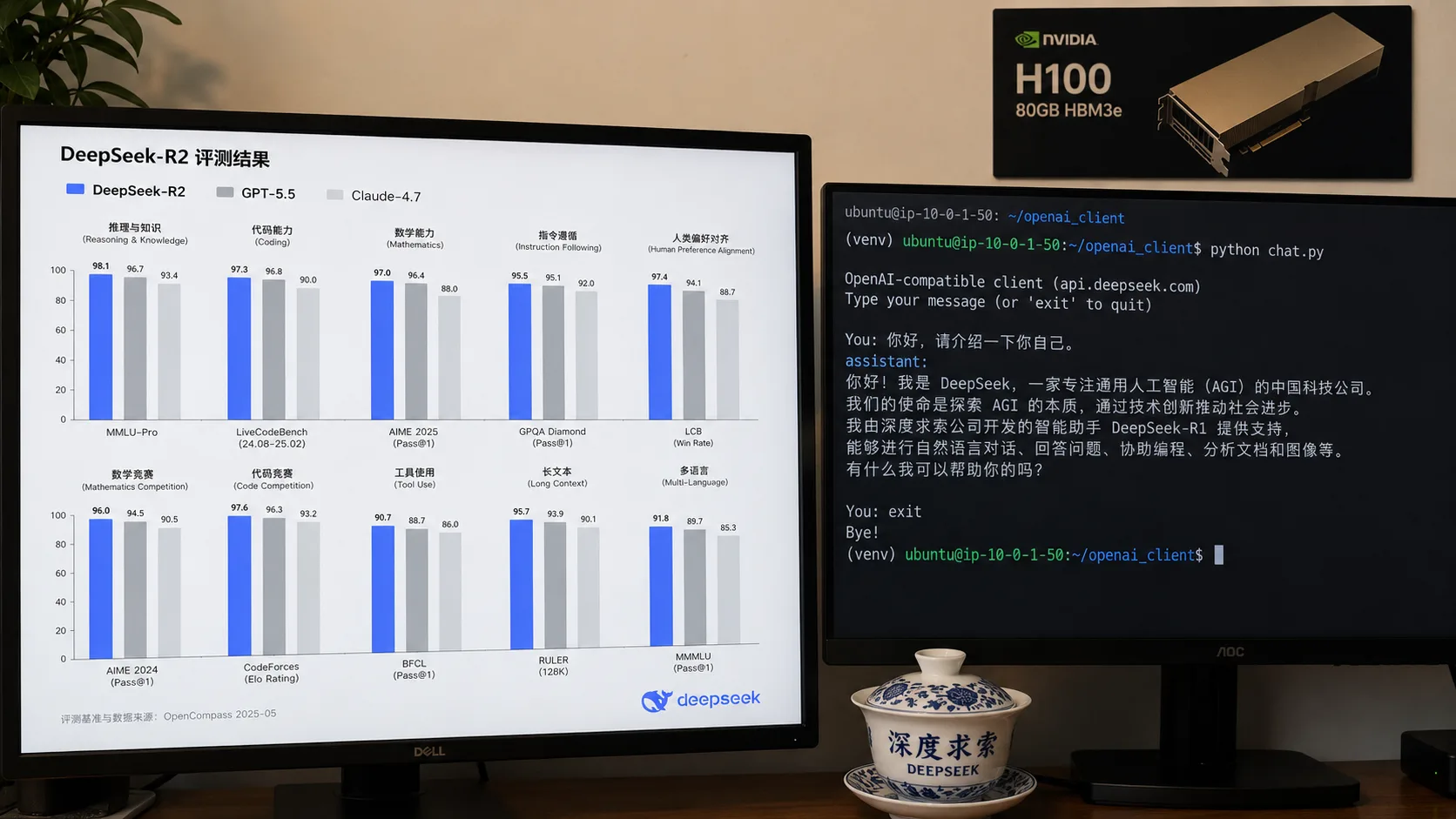
Benchmarks proyectados
Estos números son proyecciones basadas en leaks, comportamientos observados en endpoints staging, y declaraciones de DeepSeek en conferencias técnicas. Tomalos como estimación, no como medición confirmada — los publicaremos definitivos cuando R2 esté lanzado.
Generación de código
| Benchmark | DeepSeek R2 (proyectado) | GPT-5.5 | Claude 4.7 | Gemini 3.5 Pro |
|---|---|---|---|---|
| HumanEval+ | 92.3% | 96.0% | 94.8% | 91.2% |
| MBPP+ | 89.7% | 91.1% | 90.5% | 87.4% |
| SWE-bench Verified | 69.1% | 72.5% | 74.8% | 65.3% |
| SWE-bench Lite | 81.4% | 84.8% | 86.2% | 79.1% |
R2 cierra la brecha en HumanEval/MBPP a menos de 4 puntos, pero pierde más en SWE-bench (entre 5 y 6 puntos respecto a Claude 4.7). La interpretación: R2 es excelente para tareas algorítmicas aisladas pero todavía tiene gap en razonamiento sobre codebases grandes con convenciones implícitas — exactamente la dimensión donde Claude Code domina con repository intelligence.
Razonamiento general
| Benchmark | DeepSeek R2 (proyectado) | GPT-5.5 | Claude 4.7 |
|---|---|---|---|
| MMLU-Pro | 82.1% | 84.7% | 85.3% |
| GPQA Diamond | 73.4% | 78.2% | 76.9% |
| AIME 2025 | 88.0% | 86.5% | 84.1% |
| BigBench-Hard | 89.7% | 91.4% | 90.8% |
Acá la sorpresa: DeepSeek R2 supera a los modelos occidentales en AIME, el benchmark más duro de matemáticas competitivas. Esto refuerza el patrón visto en R1: los modelos chinos optimizan especialmente para razonamiento matemático y científico, posiblemente porque el currículo de training tiene mucho material de academia oriental.
Costos por millón de tokens
Acá está el argumento real para considerar DeepSeek en producción:
| Modelo | Input USD/1M tokens | Output USD/1M tokens |
|---|---|---|
| DeepSeek V4 (proyectado) | $0.27 | $1.10 |
| DeepSeek R2 (proyectado) | $0.55 | $2.19 |
| GPT-5.5 | $1.25 | $5.00 |
| Claude 4.7 | $3.00 | $15.00 |
| Gemini 3.5 Pro | $1.10 | $4.40 |
R2 sale 4.5 veces más barato que GPT-5.5 y 6.8 veces más barato que Claude 4.7 para output. Para apps que generan mucho contenido (chatbots con respuestas largas, generadores de documentos, agentes que producen código), la diferencia es sustantiva. Un proyecto que hoy gasta USD 3.000/mes en API de Claude podría pasar a USD 440 con R2 si la calidad es aceptable para el caso de uso.
Casos donde DeepSeek R2 ya gana hoy
Antes de que esté lanzado oficialmente, R1 sigue disponible y muchos equipos ya lo usan en producción. Los patrones donde DeepSeek tiene ventaja real:
- Generación masiva de contenido. Newsletters, descripciones de productos, traducciones automáticas, resúmenes. El gap de calidad es marginal y el ahorro es significativo.
- Razonamiento matemático puro. Análisis estadísticos, validación de cálculos, generación de pruebas formales. R2 con su chain-of-thought ajustado para STEM rinde como o mejor que la competencia.
- Apps con presupuesto ajustado en LatAm. Para PYMEs ecuatorianas que quieren integrar IA pero la factura mensual de OpenAI o Anthropic los asfixia, DeepSeek ofrece 80% de la calidad por 20% del precio. Es una ecuación atractiva.
- Procesamiento batch offline. Si tu workflow no necesita latencia baja en tiempo real, podés agendar inference en horarios off-peak con DeepSeek y bajar aún más el costo.
- Modelos finetuned o destilados. DeepSeek publica modelos open weights, lo que permite finetuneo y selfhosting. Para casos donde mandar datos a una API externa no es aceptable, es la única opción viable a este precio.
Donde DeepSeek todavía pierde claramente
Para no caer en hype, los casos donde Claude 4.7 o GPT-5.5 siguen ganando contundentemente:
- Codding sobre codebases grandes (>200K líneas). El gap en SWE-bench se traduce en errores reales en monorepos.
- Razonamiento legal y contractual en idiomas no-chino. Claude 4.7 sigue siendo el mejor para este tipo de análisis (ver nuestro post sobre Claude for Legal).
- Conversación natural y matiz cultural occidental. R1 a veces tiene salidas que se sienten “traducidas del chino” — frases que técnicamente correctas pero que un nativo del idioma destino nunca diría así.
- Cumplimiento regulatorio estricto en EU/US. DeepSeek está bajo escrutinio de varios reguladores occidentales por almacenamiento de datos en China. Para apps regulated (banca, salud, gobierno) el riesgo legal de usar DeepSeek puede no compensar el ahorro.
- Multimodalidad rica. R2 es solo texto. Si necesitás visión, audio o generación de imagen, seguís dependiendo de los modelos occidentales o de Qwen-VL (también de origen chino, otro proveedor distinto).
Implicaciones geopolíticas y la guerra de chips
El relato simple — China está cerrando la brecha con USA — es real pero incompleto. Lo importante para entender es el detalle táctico:
Hardware híbrido como respuesta pragmática. El uso confirmado de chips Nvidia para fine-tuning final de R2, después de pretraining mayoritario en Huawei Ascend, muestra que DeepSeek elige la herramienta correcta para cada fase. Los kernels CUDA optimizados durante una década siguen sin equivalencia abierta en el ecosistema Huawei. China va a llegar, pero todavía no llegó.
Reverse capital flow. Inversionistas de Silicon Valley están comprando posiciones en DeepSeek vía vehículos intermediarios. La separación geopolítica del mercado AI es más narrativa que real al nivel de capital — el dinero sigue el rendimiento, no las fronteras.
Modelos open weights como soft power. DeepSeek publica los weights de sus modelos bajo licencias permisivas. Esto hace que startups en LatAm, África y el sudeste asiático construyan su stack de IA con tecnología china en lugar de americana. A largo plazo, esa adopción matters tanto como la performance del modelo en sí.
Impacto en las valuaciones de Nvidia. Si R2 lanza con la performance proyectada y costo declarado, esperamos otro evento de selloff del estilo de enero de 2025 — quizás menor en magnitud porque ya no es sorpresa, pero suficiente para mover billones. Inversores que tengan exposure significativa en Nvidia conviene que monitoreen las fechas de lanzamiento de DeepSeek.
Cómo prepararte como dev en LatAm
Tres acciones concretas para los próximos 60 días:
1. Probá DeepSeek V3 hoy y mide vs tu API actual
DeepSeek V3 está disponible vía la API oficial (deepseek.com) y vía OpenRouter. Es compatible con la SDK de OpenAI, así que cambiar el endpoint y la API key te da una migración A/B en minutos:
from openai import OpenAI
cliente = OpenAI(
api_key="sk-deepseek-tu-key",
base_url="https://api.deepseek.com/v1"
)
respuesta = cliente.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "user", "content": "Tu prompt"}
]
)Corré tus prompts más comunes en paralelo con tu API actual durante una semana. Mide calidad subjetiva, costos reales, y latencia desde Ecuador. Si la calidad alcanza el 85% de tu API actual a 25% del precio, el ROI es obvio.
2. Identificá los workflows candidatos a migración
No todos tus llamados a IA son iguales. Mapealos así:
- Críticos / customer-facing / requieren máxima calidad: quedátelos en Claude 4.7 o GPT-5.5.
- Batch / background / contenido alto volumen: candidatos primarios para DeepSeek.
- Internos / debug / herramientas dev: candidatos primarios para DeepSeek.
Esa segmentación típicamente migra 40-60% del volumen a DeepSeek y baja la factura mensual entre 30 y 50%.
3. Empezá a observar los benchmarks oficiales cuando R2 lance
Cuando R2 salga, los benchmarks reales (no proyectados) van a definir si es competitivo real o solo marketing. Suscribite a Artificial Analysis, LLM-Stats, o nuestro propio newsletter — tan pronto haya números independientes te avisamos.
Tabla resumen
| Pregunta | Respuesta corta |
|---|---|
| ¿Lanzamiento de V4 y R2? | V4: junio-agosto 2026. R2: agosto-octubre 2026 |
| ¿Tamaño del modelo? | V4: ~1T total / 37B activos por token (MoE) |
| ¿Brecha vs GPT-5.5 en código? | menos de 4pp en HumanEval, ~5pp en SWE-bench |
| ¿Costo vs Claude 4.7? | ~6.8x más barato en output tokens |
| ¿Hardware de training? | Mayoritariamente Huawei + Nvidia para fine-tuning final |
| ¿Open weights? | Sí (como R1 y V3), licencia permisiva |
| ¿Soporta multimodal? | No, solo texto en R2. V4 con visión está rumoreado |
| ¿Vale probarlo desde Ecuador? | Sí, compatible con SDK OpenAI, ahorro 4-6x |
Preguntas frecuentes
¿DeepSeek es seguro de usar si manejo datos sensibles?
¿Qué pasa con DeepSeek si EEUU sanciona más fuerte?
¿Realmente la calidad de DeepSeek alcanza para producción seria?
¿Puedo correr DeepSeek R2 en mi propio servidor cuando salga?
¿Cómo se compara DeepSeek con Qwen de Alibaba?
¿La nueva versión de DeepSeek va a romper apps que ya usan V3?
¿Vale la pena el riesgo geopolítico para una startup ecuatoriana?
¿Qué pasa con la latencia desde Ecuador hacia DeepSeek vs OpenAI o Anthropic?
Azirgo
¿Listo para construir tu Producto Digital?
Sitios web, apps móviles, software a medida y soluciones blockchain. Cuéntanos qué tienes en mente y armamos un plan claro contigo.
- Cotización clara en 48 horas
- Equipo en Ecuador, atención en español
- Desde un MVP hasta un producto en producción