Google hizo el 19 de mayo de 2026 algo que ningún laboratorio había hecho hasta ahora: presentó un modelo de la línea Flash (la barata, la rápida, la de “no es la insignia”) que supera al Pro de la generación anterior. Gemini 3.5 Flash, anunciado en la keynote de I/O 2026, le gana a Gemini 3.1 Pro en casi todos los benchmarks de coding y agentic workflows, corre 4x más rápido que otros modelos de frontera en throughput de tokens, y cuesta menos de la mitad para tareas agentic comparables. La versión Pro llega “el próximo mes” pero el mensaje del anuncio fue claro: el Flash ya es suficiente para la mayoría de los productos que estás construyendo.
Este post desarma qué se lanzó exactamente, qué dicen los benchmarks (con los nombres reales, no las gráficas vagas), cómo encaja con Antigravity 2.0 — el nuevo IDE agent-first de Google que reemplaza a Gemini CLI — y qué deberías mover en tu stack si hoy dependés de OpenAI, Anthropic o de Gemini 3.1 Flash. Si tu unidad económica vive de costos por token, leelo dos veces.
Qué se lanzó hoy en I/O 2026
El anuncio tiene cuatro piezas que conviene separar.
Gemini 3.5 Flash es generalmente disponible desde hoy en todos los canales: la app Gemini, AI Mode en Google Search, la Gemini API a través de AI Studio y Android Studio, y el Gemini Enterprise Agent Platform sobre Vertex AI. No es preview, no es waitlist, no es “rolling out”. Es GA con SLA público.
Gemini 3.5 Pro llega “el próximo mes” según el blog oficial. Google admitió que ya lo usa internamente y que es el motor detrás de varias features que mostraron en demos en la keynote (incluyendo razonamiento sobre videos de YouTube de varias horas y generación de UIs interactivas). El rollout público arranca con AI Ultra y Workspace Enterprise.
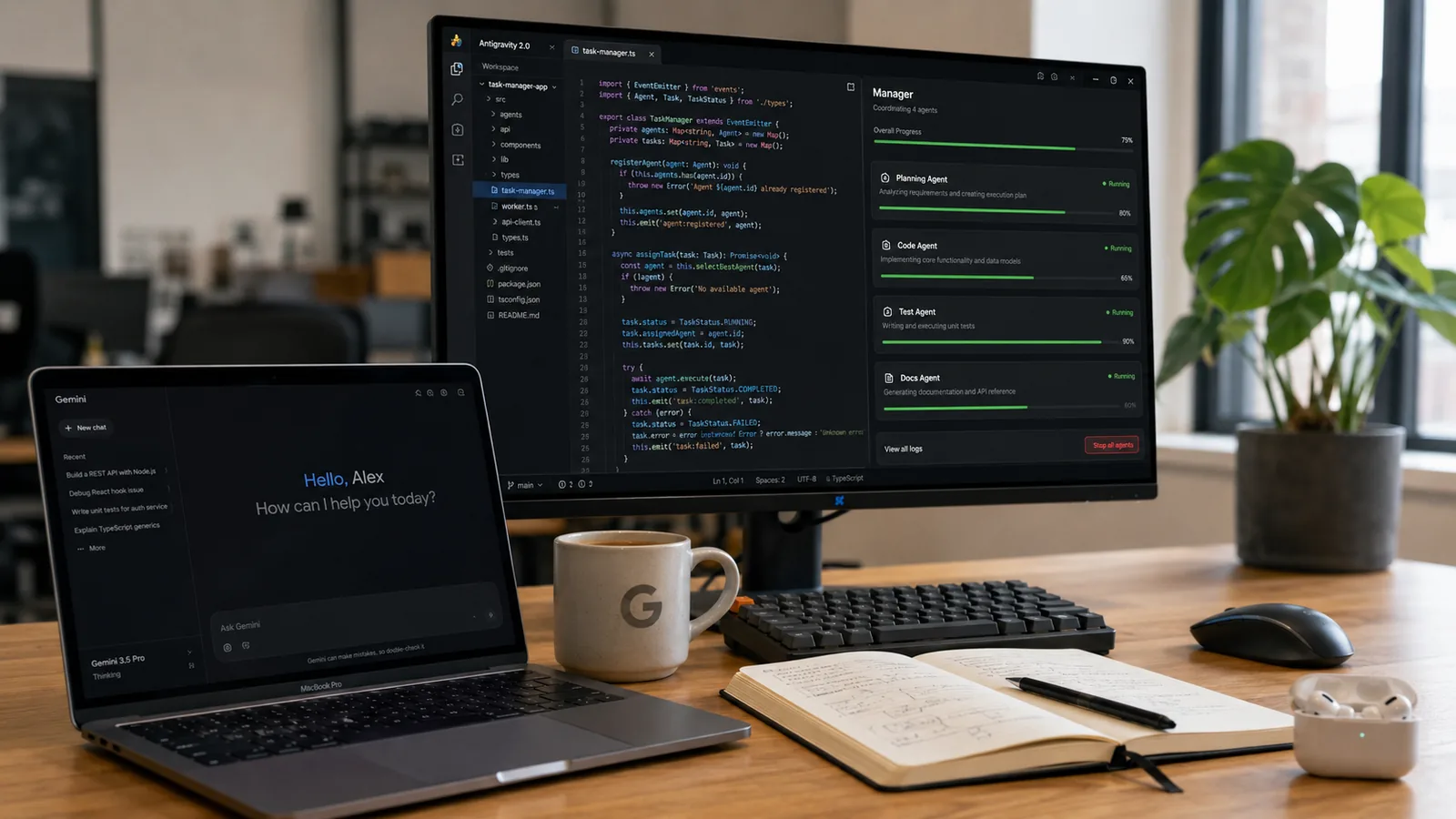
Antigravity 2.0 es la apuesta de IDE agent-first de Google. Es un cliente desktop dedicado (no una extensión de VS Code) que compite directo contra Cursor, Windsurf y Codex Mobile. Soporta Gemini 3.5 nativamente pero también Claude Sonnet 4.6, Claude Opus 4.6 y variantes open de OpenAI. Reemplaza al viejo Gemini CLI — que ya no recibirá features nuevas.
Gemini Spark es un agente personal 24/7 corriendo sobre Gemini 3.5 Flash. La primera ola es para trusted testers de Google; la beta pública arranca para suscriptores de Google AI Ultra en Estados Unidos. LatAm queda fuera del piloto inicial, como suele pasar.
Los números: benchmarks y velocidad
Acá están los datos del modelo Flash que dio Google en su post oficial de anuncio. No hay maquillaje — son los benchmarks que importan para developers.
| Benchmark | Qué mide | Gemini 3.5 Flash |
|---|---|---|
| Terminal-Bench 2.1 | Capacidad de operar en terminales como agente | 76.2% |
| GDPval-AA | Razonamiento experto en dominios productivos | 1656 Elo |
| MCP Atlas | Uso correcto del Model Context Protocol | 83.6% |
| CharXiv Reasoning | Razonamiento multimodal sobre gráficos científicos | 84.2% |
El número que va a aparecer en todos los hilos de Twitter / X es ese 4x más rápido que otros modelos de frontera en throughput de tokens por segundo. Eso lo pone en la misma liga de latencia que los LPUs de Groq que NVIDIA acaba de absorber, pero servido por la infraestructura de Google sin requerir cambio de proveedor. Para apps con voz, copilots de código en tiempo real o agentes con muchos tool calls encadenados, ese 4x es la diferencia entre “usable” e “inusable”.
El otro número, menos vistoso pero más importante para tu balance, es el costo agentic. Google declara “menos de la mitad” del costo de modelos comparables (sin nombrar nombres, pero claramente apuntando a Claude Sonnet 4.6 y GPT-5.5). Los precios oficiales en la Gemini API rondan los USD 0.50 por millón de tokens de entrada y USD 3.00 por millón de tokens de salida para Flash, con context window de 1,048,576 tokens (1M) y output máximo de 65,536 tokens por respuesta. El input multimodal acepta texto, imágenes, audio, video y PDFs; el output es solo texto.
Para contexto, esto se suma al patrón que cubrimos en NVIDIA + Groq: la era de la inferencia barata: los costos de inferencia están cayendo más rápido que los precios. Lo que hoy cuesta USD 3 por millón de tokens en Gemini 3.5 Flash costaba USD 15 hace 12 meses en GPT-4 Turbo, capacidades comparables. El piso sigue bajando.
Gemini 3.5 Pro: lo que viene en junio
El blog oficial deja a Pro como un teaser pero no da números. Lo que sí confirmó Google es que el Pro ya está corriendo internamente y que es el motor detrás de tres demos que vimos en la keynote:
- Razonamiento sobre videos de varias horas sin pre-resumen (relevante para video understanding en streaming, vigilancia, e-learning).
- Generación de UIs web ricas e interactivas directamente desde un prompt — no markup estático, sino componentes con estado y handlers cableados.
- Subagentes desplegados en paralelo para tareas que se descomponen naturalmente (revisión de codebase, multi-step research, scraping con normalización).
La pregunta práctica es: ¿vale la pena esperar a Pro o empezar con Flash hoy? La respuesta para el 80% de los casos es empezá con Flash. La keynote dejó claro que Flash supera a Pro de la generación anterior, así que tu app sobre 3.5 Flash va a estar por encima de cualquier app que hoy corra sobre 3.1 Pro o equivalente. Cuando salga 3.5 Pro vas a poder hacer upgrade con un cambio de string en la config, no de arquitectura.
El 20% restante son casos donde el costo no es restricción (research, multimodal con contexto extremo, agentes muy autónomos) y donde 3.5 Pro va a justificar el premium en USD por mil tokens. Para esos, esperá unas semanas y comparalos directo.
Antigravity 2.0: la apuesta de Google al IDE agent-first
Antigravity 2.0 es el otro headline del día y merece su propio análisis. Es el cliente desktop que Google empuja como reemplazo del workflow IDE + LLM como sidebar que dominó 2024-2025. La idea es invertir la jerarquía: en Antigravity los agentes son ciudadanos de primera clase, no plugins.
Las dos vistas principales son:
- Editor view: una interfaz tipo VS Code con un agente lateral. Familiar, sin sorpresas. Sirve para developers que recién migran desde Cursor o Codex.
- Manager view: el centro de orquestación, donde ves múltiples agentes corriendo en paralelo a través de workspaces. Cada agente genera Artifacts — task lists, planes de implementación, screenshots, grabaciones del navegador. Vos revisás los Artifacts (no las líneas individuales) y dejás feedback que el agente incorpora sin frenar la ejecución.
El cambio mental es grande. Pasás de “yo escribo código, la IA me autocompleta” a “yo defino tareas, varios agentes las ejecutan en paralelo, yo verifico los resultados”. El post de Google Developers lo describe como “operar a un nivel más alto, orientado a tareas, no a archivos”.
Hay tres detalles que vale la pena destacar para developers en LatAm:
- Antigravity soporta múltiples modelos — Gemini 3.5 Flash y Pro nativamente, pero también Claude Sonnet 4.6, Claude Opus 4.6 y variantes open de OpenAI. No es lock-in cerrado a Google.
- Protocolo Agent-to-Agent (A2A) — Google propone un estándar para comunicación entre agentes que ya tiene interop con LangChain y AutoGen. Si tu equipo construyó agentes sobre otros frameworks, podés integrarlos con Antigravity sin reescribir.
- Gemini CLI está siendo descontinuado — todas las features nuevas van a Antigravity CLI. Si tu pipeline depende de Gemini CLI, planificá migración para los próximos meses.
Si querés profundizar en qué editor agent-first conviene hoy, el análisis que hicimos en Cursor 3 vs Windsurf en 2026 sigue vigente como marco mental, ahora con Antigravity como tercer jugador serio.
Gemini Spark: el agente personal 24/7
Spark es la apuesta de Google al “agent personal que vive en tu vida digital”. Corre sobre Gemini 3.5 Flash, opera 24/7, y tiene acceso (con tu consentimiento) a Gmail, Calendar, Drive, Photos, Maps y Chrome. La idea es que Spark agenda tus citas, te recuerda follow-ups, prepara resúmenes de reuniones que vienen, y ejecuta tareas multi-paso (reservar restaurante, comprar un vuelo, organizar un viaje) sin que tengas que abrir 5 apps.
Los detalles concretos:
- Acceso: trusted testers de Google ya tienen el preview. La beta pública arranca para suscriptores de Google AI Ultra en Estados Unidos primero. Ecuador, Colombia y el resto de LatAm quedan para “rollout posterior” sin fecha.
- Modelo: Gemini 3.5 Flash con tools propios de Google Workspace y third-party (via OAuth).
- Privacidad: Google declaró que Spark no entrena con tus datos personales y que cumple el Frontier Safety Framework con safeguards CBRN (Chemical, Biological, Radiological, Nuclear) reforzados.
La movida estratégica es clara: si OpenAI tiene ChatGPT como su producto consumer, y Anthropic tiene Claude como su producto B2B, Google necesitaba un consumer-facing agent diferenciado. Spark es esa pieza. La pregunta abierta es si la gente va a confiarle a un agente acceso completo a su Gmail y Calendar. Históricamente Google sufrió porque los usuarios no confían en ese nivel de acceso. Spark va a ser un termómetro útil de esa confianza.
Cómo usar Gemini 3.5 Flash hoy
Cinco pasos concretos para integrarlo en una app que ya tenés corriendo.
- Conseguí una API key: andá a
aistudio.google.com, sign-in con tu cuenta Google, y generá una key en el panel de API keys. Es gratis hasta el primer rate limit (10 RPM en free tier, sube a 1000 RPM en paid). - Instalá el SDK oficial: para JavaScript/TypeScript,
@google/generative-ai. Para Python,google-generativeai. Ambos tienen el mismo shape de API que sus contrapartes en1.5y3.x, así que la migración es cambiar el stringgemini-3.1-flashporgemini-3.5-flash. - Configurá thinking levels: 3.5 Flash acepta cuatro niveles de razonamiento (
minimal,low,medium,high). Default eslow. Para coding y tareas complejas subí amedium. Para chat simple bajá aminimaly vas a ahorrar 60-70% de costo. - Habilitá context caching: la API cachea automáticamente prefijos repetidos. Si tu app re-envía el mismo system prompt en cada call, vas a ahorrar hasta 75% del costo de input. No requiere código adicional — es default.
- Llamada mínima:
import { GoogleGenerativeAI } from "@google/generative-ai"
const genAI = new GoogleGenerativeAI(process.env.GEMINI_API_KEY!)
const model = genAI.getGenerativeModel({
model: "gemini-3.5-flash",
generationConfig: {
temperature: 0.7,
maxOutputTokens: 8192,
thinkingLevel: "medium",
},
})
const result = await model.generateContent("Explicá qué hace `useMemo` en React 19")
console.log(result.response.text())Para streaming, cambiá generateContent por generateContentStream y await for ... of result.stream.
Si tu app hoy corre sobre OpenAI o Anthropic y querés probar sin reescribir, Vercel AI SDK ya tiene adapter para Gemini 3.5 desde día uno. Cambiá el provider y los tres benchmarks que importan (velocidad, costo, calidad) se vuelven comparables sin tocar tu UI.
Cómo se compara con Claude 4.7 y GPT-5.5
Comparativa al 19 de mayo de 2026 con los precios y números públicos de cada modelo en su tier comparable (Flash / Sonnet / mid-tier).
| Métrica | Gemini 3.5 Flash | Claude Sonnet 4.6 | GPT-5.5 |
|---|---|---|---|
| Context window | 1M tokens | 1M tokens (1M release) | 400K tokens |
| Costo input (USD/M tokens) | 0.50 | 3.00 | 1.25 |
| Costo output (USD/M tokens) | 3.00 | 15.00 | 10.00 |
| Output máximo | 65K tokens | 64K tokens | 16K tokens |
| Throughput (tok/s)* | 4x baseline | baseline | baseline |
| Multimodal input | texto, img, audio, video, PDF | texto, img, PDF | texto, img |
| Reasoning levels | minimal/low/medium/high | thinking mode (on/off) | reasoning_effort (low/med/high) |
*Throughput es relativo según la métrica de Google; los números absolutos varían por región.
La lectura honesta: Gemini 3.5 Flash es el mejor deal de mercado en mayo 2026 para casos agentic de volumen medio-alto. Claude Sonnet 4.6 gana en razonamiento complejo y en escritura de código intricate; lo cubrimos en detalle en Claude 4.7: lo que cambia para developers. GPT-5.5 gana cuando ya vivís en el ecosistema OpenAI con Codex y agentes propios; ese análisis está en GPT-5.5: qué cambia para developers.
Para apps nuevas en LatAm con presupuesto ajustado, Flash es el default razonable. Para verticales regulados (legal, salud, finanzas) donde el costo es secundario y la calidad de razonamiento es primaria, Sonnet/Opus de Anthropic siguen siendo la elección segura.
Qué cambia para devs en LatAm
Cuatro lecturas concretas.
Primera: el costo deja de ser excusa para no enviar IA. USD 0.50/M tokens de input significa que una app con 100K usuarios mensuales haciendo 5 calls cada uno (500M tokens/mes input, ~50M output) sale en USD 400 al mes. Es comparable al costo de un servidor mediano en Hetzner. Cualquier producto SaaS rentable puede absorberlo.
Segunda: la latencia llega a niveles de UI nativa. Con 4x throughput vs. modelos previos, una respuesta corta (200 tokens) sale en ~300-400 ms desde us-east-1 a Quito. Eso es debajo del umbral de percepción para la mayoría de UIs. Tu app puede usar IA en flows donde antes era prohibitivo (autocomplete inteligente en formularios, validación contextual, traducción inline).
Tercera: Antigravity te da otra opción de IDE sin lock-in. Hoy tenés Cursor, Windsurf, Codex y ahora Antigravity. Las cuatro soportan Claude, Gemini y OpenAI con grados distintos de profundidad. El mercado de IDEs agent-first se commoditizó en 6 meses; elegí por UX y workflow, no por modelo subyacente.
Cuarta: el A2A protocol abre el ecosistema de agentes. Si tu equipo construyó un agente en LangChain, AutoGen o un framework propio, podés interoperar con agentes de Antigravity (o de cualquier otro vendor que adopte A2A) sin reescribir. Para LatAm, donde los equipos suelen tener herramientas heterogéneas, este interop es más útil que la suma de las features individuales.
Riesgos y consideraciones
Cuatro temas para pensar antes de mover producción a Gemini 3.5 Flash.
El rollout es gradual por región. Google declara GA pero la latencia real depende de la región más cercana al cliente. Para Ecuador y región andina, el endpoint más cercano es us-east1 (South Carolina) o southamerica-east1 (São Paulo). Si tu app es latency-sensitive y vivís en LatAm, medí ambos endpoints antes de comprometerte.
El context caching es automático pero opaco. Google no expone aún las métricas detalladas de cache hit rate en producción. Si tu unidad económica depende de cache, instrumentá vos mismo el ahorro o usá Vertex AI donde sí hay métricas detalladas.
Las features de Gemini Spark requieren acceso a Workspace. Si construís un producto para una empresa con Google Workspace Enterprise, hay un camino claro. Si la empresa usa Microsoft 365 o stack mixto, Spark no aplica — y la integración con M365 sigue siendo terreno de Microsoft Copilot.
El Frontier Safety Framework tiene latencia adicional. Las CBRN safeguards reforzadas agregan ~50-100 ms a cada call. Es invisible para chat pero medible en latencia inter-token de agentes. Tenelo en cuenta si construís para tiempo real estricto.
Tabla resumen
| Pregunta | Respuesta corta |
|---|---|
| ¿Cuándo se lanzó Gemini 3.5 Flash? | 19 de mayo de 2026 en Google I/O |
| ¿Cuándo llega Gemini 3.5 Pro? | ”Próximo mes” — junio de 2026 |
| ¿Costo de Gemini 3.5 Flash? | USD 0.50/M tokens input, USD 3.00/M output |
| ¿Context window? | 1M tokens; output máximo 65K |
| ¿Velocidad vs rivales? | 4x más tokens/seg en frontera |
| ¿Multimodal? | Sí: texto, imágenes, audio, video, PDFs |
| ¿Reemplaza a Gemini CLI? | Sí — la nueva herramienta es Antigravity CLI |
| ¿Disponible en Ecuador? | Sí, vía Gemini API en AI Studio y Vertex AI |
Preguntas frecuentes
¿Gemini 3.5 Flash realmente supera a Gemini 3.1 Pro?
¿Vale la pena migrar de Gemini 3 Flash a Gemini 3.5 Flash?
¿Cómo se compara con Claude Sonnet 4.6 en código?
¿Qué pasa con Gemini CLI? ¿Sigue funcionando?
¿Puedo usar Gemini 3.5 Flash desde un proyecto Astro o Next.js?
¿Gemini Spark llega a Ecuador?
¿Antigravity reemplaza a Cursor o Windsurf?
¿Por qué Google sacó Flash antes que Pro esta vez?
Azirgo
¿Listo para construir tu Producto Digital?
Sitios web, apps móviles, software a medida y soluciones blockchain. Cuéntanos qué tienes en mente y armamos un plan claro contigo.
- Cotización clara en 48 horas
- Equipo en Ecuador, atención en español
- Desde un MVP hasta un producto en producción