Durante años “IA en el navegador” significó pegarle a una API en la nube — OpenAI, Anthropic, Google — y aceptar la latencia, el costo por token y el viaje de datos del usuario hasta servidores ajenos. El Prompt API de Chrome rompe ese patrón: trae un modelo Gemini Nano corriendo directo sobre la GPU del usuario, sin red, sin tokens facturados, sin que el dato salga del dispositivo. Es la base de un género nuevo de features — resumen instantáneo de páginas, autocompletado contextual, clasificación de inputs — que hasta hace seis meses requerían un backend.
La API se llama oficialmente LanguageModel y vive sobre el global del mismo nombre (algunas referencias viejas todavía la llaman window.ai, pero ya se renombró). En Chrome 138+ está estable para extensiones y disponible detrás de un flag en páginas web. Soporta multimodal — texto, imagen, audio — streaming token a token, y structured output con JSON Schema. Si construís frontends y todavía no la probaste, este post te lleva del feature detection a un caso real útil en producción.
Qué es exactamente el Prompt API
El Prompt API es la interfaz JavaScript que Chrome expone para interactuar con Gemini Nano, el modelo small-language que Google distribuye dentro del navegador. Nano es un modelo de ~4GB optimizado para correr sobre la GPU del usuario vía WebGPU, descargado una sola vez por el navegador y compartido entre todos los sitios que lo usen.
Los puntos clave:
- On-device, sin red. El modelo corre localmente. Los prompts y respuestas nunca salen del dispositivo del usuario.
- Cero costo por token. No hay facturación porque no hay servidor que pague. El costo es la batería del usuario y la VRAM.
- Latencia muy baja. Sin viaje a la nube, el primer token aparece en 100-300ms en hardware decente.
- Privacidad por diseño. Útil para casos sensibles: extraer datos de un PDF subido por el usuario, clasificar emails personales, resumir el contenido de un input antes de mandarlo a cualquier lado.
- Limitado en capacidades. Nano no compite con GPT-5.5 o Claude 4.7. Es ideal para tareas acotadas y costosas de hacer en red — resumir, clasificar, reescribir, extraer estructura.
La comparación honesta: Nano es a Gemini Pro lo que SQLite es a Postgres. No vas a entrenar a tu CRM con esto, pero vas a resolver el 70% de los “necesito un mini-LLM rápido” sin pagar un dólar.
Disponibilidad real en mayo de 2026
Antes del primer LanguageModel.create() conviene saber dónde funciona y dónde no:
| Contexto | Estado | Cómo activarlo |
|---|---|---|
| Extensiones Chrome | Estable desde Chrome 138 | Permission aiLanguageModel en manifest.json |
| Páginas web | Detrás de flag | chrome://flags/#prompt-api-for-gemini-nano |
| Origin Trial público | Activo | Registro en developer.chrome.com con tu origen |
| Edge | Heredando de Chromium | Disponibilidad parcial en Canary |
| Safari / Firefox | No soportado | Apple y Mozilla no han adoptado el estándar |
Para que el modelo realmente cargue el usuario necesita además:
- Chrome 138 o superior en desktop (Windows, macOS, Linux ChromeOS).
- 22GB de espacio libre la primera vez para descargar el modelo.
- Una GPU con al menos 4GB de VRAM (la mayoría de equipos post-2020 sirve).
- No estar en modo medido (Chrome no descarga Nano sobre redes con costo).
Sí, eso descarta a una parte importante del público hispanohablante en dispositivos viejos. La lógica de feature detection que vas a usar siempre asume que el API puede no estar disponible y degrada al fallback en la nube.
Hello world: tu primer prompt en el navegador
El patrón estándar para usar el Prompt API es: detectar disponibilidad, crear sesión, mandar prompt. Mínimo viable:
async function holaNano() {
if (!("LanguageModel" in self)) {
console.warn("Prompt API no disponible")
return null
}
const disponibilidad = await LanguageModel.availability()
if (disponibilidad === "unavailable") {
return null
}
const sesion = await LanguageModel.create({
initialPrompts: [
{ role: "system", content: "Sos un asistente conciso. Responde en español." },
],
})
const respuesta = await sesion.prompt("¿Qué es el Prompt API en una frase?")
sesion.destroy()
return respuesta
}LanguageModel.availability() devuelve uno de cuatro valores: "unavailable", "downloadable", "downloading", o "available". Manejar los cuatro es importante para UX: si el modelo está downloadable, podés ofrecer un botón “descargar IA local (4GB)” antes de bloquear la feature. Si está downloading, mostrale al usuario una barra de progreso vía LanguageModel.create({ monitor }).
Notá tres detalles del código: usamos initialPrompts con un mensaje system para fijar el comportamiento; siempre llamamos sesion.destroy() cuando terminamos para liberar VRAM; y la API es async porque la sesión puede tardar 100-500ms en inicializar la primera vez.
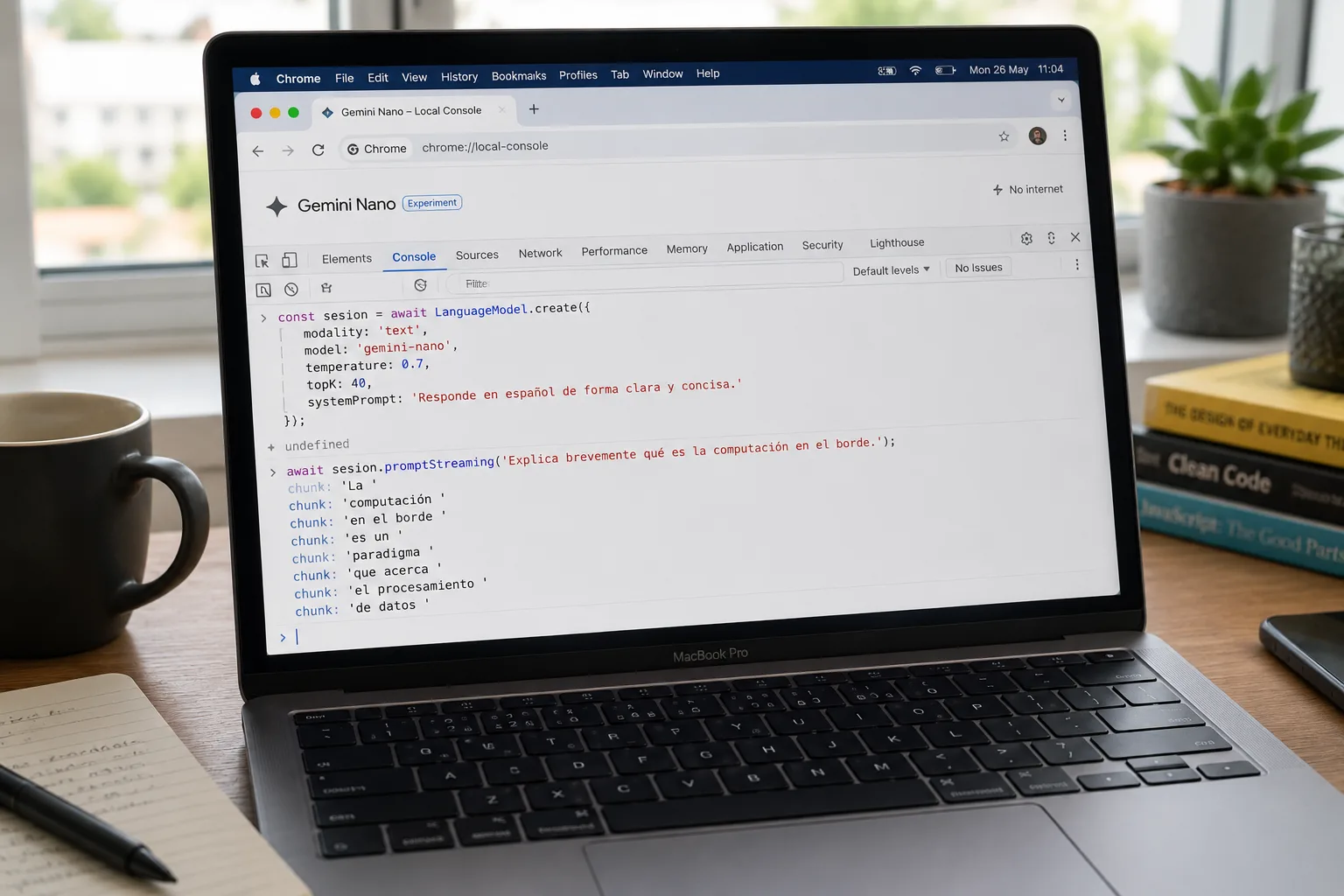
Streaming: respuesta token a token
Para cualquier output que el usuario va a leer, streaming es obligatorio. Hace que la respuesta se sienta instantánea aunque la generación tome 2-3 segundos completos.
const sesion = await LanguageModel.create({
initialPrompts: [
{ role: "system", content: "Resumí el texto en máximo 3 bullets." },
],
})
const texto = document.querySelector("#articulo").innerText
const stream = sesion.promptStreaming(`Resumí esto:\n\n${texto}`)
const output = document.querySelector("#resumen")
for await (const chunk of stream) {
output.textContent += chunk
}
sesion.destroy()promptStreaming() devuelve un ReadableStream<string> que iterás con for await. Cada chunk es un fragmento incremental — no la respuesta completa, solo lo nuevo desde el chunk anterior. El patrón es exactamente el mismo que con la SDK de Anthropic o la de OpenAI, así que migrar código existente es trivial.
Multimodal: prompts con imagen y audio
Acá Nano gana protagonismo. Crear una sesión con inputs multimodales se hace declarando explícitamente los tipos esperados:
const sesion = await LanguageModel.create({
expectedInputs: [
{ type: "text", languages: ["es", "en"] },
{ type: "image" },
{ type: "audio" },
],
expectedOutputs: [{ type: "text", languages: ["es"] }],
})Una vez creada, podés mandar prompts con piezas mezcladas. Ejemplo: comparar dos screenshots y describir la diferencia.
const img1 = await fetch("/captura-antes.png").then((r) => r.blob())
const img2 = await fetch("/captura-despues.png").then((r) => r.blob())
const respuesta = await sesion.prompt([
{ type: "text", value: "Describí las diferencias visuales entre estas dos imágenes." },
{ type: "image", value: img1 },
{ type: "image", value: img2 },
])
console.log(respuesta)Para audio el patrón es idéntico, usando un AudioBuffer o un Blob con audio. Útil para transcripciones cortas, detección de comandos de voz, clasificación de tono. Importante: multimodal output sigue limitado a texto — Nano no genera imágenes ni audio, solo los consume.
Structured output: JSON con schema
El caso de uso más interesante para apps reales: pedirle a Nano que devuelva JSON validable. El API soporta responseFormat con JSON Schema, lo que constraint-decodes el output para garantizar que el JSON parsea siempre.
const schema = {
type: "object",
properties: {
sentimiento: { type: "string", enum: ["positivo", "neutral", "negativo"] },
temas: { type: "array", items: { type: "string" }, maxItems: 5 },
spam: { type: "boolean" },
},
required: ["sentimiento", "spam"],
}
const sesion = await LanguageModel.create()
const review = "El producto llegó tarde pero la calidad superó mis expectativas."
const json = await sesion.prompt(
`Clasificá esta reseña:\n${review}`,
{ responseFormat: { type: "json_schema", schema } }
)
const datos = JSON.parse(json)
sesion.destroy()En la práctica, Nano sigue produciendo JSON malformado en ~5% de los casos cuando el schema es complejo (el constrained decoding no es perfecto todavía). Para producción, envolvé el JSON.parse en un try/catch y reintentá una vez si falla. Para schemas simples — clasificación binaria, enums, extracciones planas — la tasa de éxito sube a 99%+.
Cuándo usar Nano vs una API cloud
Esta es la decisión real que tu equipo va a tener que tomar. No hay regla universal, pero sí dos columnas claras:
| Criterio | Nano local | API cloud (Gemini Pro, Claude, GPT) |
|---|---|---|
| Costo por consulta | Cero (batería del usuario) | USD 0.001-0.05 |
| Latencia primer token | 100-300ms | 400-1500ms |
| Calidad de razonamiento | Limitada | Alta |
| Contexto máximo | ~4K tokens | 200K-1M tokens |
| Privacidad | Datos nunca salen del dispositivo | Datos cruzan la nube del proveedor |
| Disponibilidad | Solo en Chrome 138+ con flag | Universal con red |
| Offline | Funciona | No funciona |
| Capacidad multimodal | Texto + imagen + audio (limitada) | Mucho más amplia, con generación de imágenes |
Reglas prácticas que ya estamos usando en producción:
- Tareas binarias o de clasificación corta (¿este input es spam?, ¿este texto está en español?, ¿esta consulta es urgente?) → Nano. Es casi gratis y la calidad alcanza.
- Resúmenes de texto del propio usuario (resumir un email que el usuario está escribiendo, una página que está leyendo) → Nano, especialmente por privacidad.
- Respuestas conversacionales largas, código generado, razonamiento complejo → Cloud, sin discusión.
- Features donde el usuario podría no tener Chrome o no tener Nano descargado → Cloud con fallback automático. El patrón: intentar Nano, si falla pegar a la API cloud.
El patrón híbrido es el que más rinde. Algo así:
async function clasificarTexto(texto) {
if ("LanguageModel" in self) {
const status = await LanguageModel.availability()
if (status === "available") {
const s = await LanguageModel.create()
const r = await s.prompt(`Clasificá: ${texto}`, {
responseFormat: { type: "json_schema", schema: clasificacionSchema },
})
s.destroy()
return JSON.parse(r)
}
}
return await clasificarViaApiCloud(texto)
}Usuario con Nano disponible: respuesta instantánea, costo cero. Usuario sin Nano: tu API cloud sigue funcionando. La misma feature, sin código duplicado.
Limitaciones reales que vas a chocar
Conviene saber dónde Nano todavía falla antes de meterlo en producción.
Calidad de español. Nano fue entrenado mayoritariamente en inglés. En español funciona pero comete errores que un modelo cloud no comete — confunde género de sustantivos, traduce mal modismos, a veces responde en inglés cuando le mandás un prompt en español sin instrucción explícita. Siempre incluí un system prompt en español y, para textos sensibles, validá el output.
Contexto corto. El contexto efectivo de Nano ronda los 4K tokens en Chrome 138-148. Si necesitás resumir un documento de 50 páginas, vas a tener que chunkearlo y resumir por partes, igual que en 2023 con los primeros GPT.
Determinismo. Igual que cualquier LLM, las salidas varían entre runs. El parámetro temperature ayuda a estabilizar (pasale temperature: 0 para máxima determinismo) pero no garantiza idéntico output.
Estado del modelo. Si el usuario tiene poco espacio en disco, Chrome purga el modelo automáticamente. La feature puede dejar de funcionar entre sesiones sin que el usuario haga nada. Manejá LanguageModel.availability() === "downloadable" después del primer uso.
API en evolución. El nombre cambió de window.ai a LanguageModel global, los parámetros se siguen ajustando, y los breaking changes son posibles hasta que la API salga de origin trial completamente (estimado Chrome 150-152). Lockear tu lógica detrás de una función wrapper para poder migrar rápido.
La crítica honesta: fragmentación del estándar
Hay una discusión legítima en la comunidad sobre si Chrome avanzó demasiado solo. Apple y Mozilla no participaron del diseño del Prompt API, y la W3C TAG (Technical Architecture Group) publicó dudas sobre incluir un modelo específico (Gemini Nano) directo en el navegador. Si Edge, Safari y Firefox no adoptan la API tal cual, tenés un estándar de facto solo-Chrome — similar a lo que pasó con WebSQL en 2010 antes de ser deprecado.
La probabilidad de que se vuelva estándar real depende de tres cosas: si Mozilla acepta correr Llama en lugar de Nano, si Apple expone una API similar sobre sus modelos on-device del Foundation Model framework, y si el W3C Web Machine Learning Community Group logra abstraer la interfaz para que sea agnóstica del modelo subyacente. En mayo de 2026 las tres están en discusión activa pero ninguna está resuelta.
Conclusión práctica: úsalo, pero envolvelo. Toda llamada al Prompt API detrás de tu propia función de utilidad. Si en seis meses Chrome cambia la API, tocás un solo archivo.
Tabla resumen
| Pregunta | Respuesta corta |
|---|---|
| ¿Qué es el Prompt API? | API JavaScript de Chrome para usar Gemini Nano localmente |
| ¿Costo? | Cero — corre on-device |
| ¿Disponibilidad? | Chrome 138+ en extensiones, flag en páginas web |
| ¿Tamaño del modelo? | ~4GB descargados una vez |
| ¿Soporta multimodal? | Sí: texto, imagen, audio como input. Solo texto como output |
| ¿Streaming? | Sí, vía promptStreaming() |
| ¿Structured output? | Sí, con JSON Schema constraints |
| ¿Cuándo no usarlo? | Razonamiento complejo, contextos largos, browsers no-Chrome |
Preguntas frecuentes
¿El Prompt API funciona en móvil?
¿Cuándo conviene usar Gemini Nano vs Gemini Pro vía API?
¿Mis datos del prompt van a Google si uso Nano?
¿Qué pasa si el usuario tiene un equipo viejo sin GPU?
¿Cuál es la diferencia entre el Prompt API y APIs especializadas como Summarizer y Translator?
¿Cómo manejo el caso donde el modelo todavía no se descargó?
¿Puedo usar el Prompt API junto con WebMCP?
¿Qué pasa con la batería del usuario cuando uso Nano intensivamente?
Azirgo
¿Listo para construir tu Producto Digital?
Sitios web, apps móviles, software a medida y soluciones blockchain. Cuéntanos qué tienes en mente y armamos un plan claro contigo.
- Cotización clara en 48 horas
- Equipo en Ecuador, atención en español
- Desde un MVP hasta un producto en producción