Durante dos años la conversación sobre video generativo se redujo a “qué tan parecido a Sora se ve”. Sora, Veo, Runway, Kling, Pika — todos pelearon por el mismo eje: realismo del clip generado desde un prompt de texto. El 19 de mayo de 2026 Google cambió la pregunta. Gemini Omni, anunciado en I/O 2026, no compite por “el clip más realista”. Compite por algo distinto: convertir cualquier combinación de inputs — texto, imágenes, audio, otros videos — en un video coherente, y permitir editarlo conversacionalmente sin abrir un timeline.
El primer modelo de la familia, Gemini Omni Flash, ya está disponible. No es preview, no es waitlist regional, no es “rolling out lentamente”. Salió a producción el mismo día del anuncio en la app Gemini, en Flow (el editor creativo de Google) y — la noticia más subestimada — gratis dentro de YouTube Shorts y la app YouTube Create. Eso último cambia el cálculo económico para creadores de contenido en LatAm de manera material: ya no necesitás pagar Runway, RunwayML, ni Sora Premium si tu output final vive en YouTube.
Este post desarma qué es Omni exactamente, qué puede hacer hoy, qué deja explícitamente fuera (la respuesta sorprende), cómo se compara con Veo 3.1 — que reemplaza — y con Sora 2, Runway Gen-4 y Kling 2.0, y qué casos de uso tiene sentido explorar primero si vivís en Ecuador o LatAm.
Qué es Gemini Omni y por qué importa
Gemini Omni es un modelo generativo multimodal con razonamiento Gemini integrado. Esa última parte es la clave. Hasta Omni, los modelos de video generativo funcionaban como sistemas separados: un encoder multimodal por un lado, un generador de video por el otro, pegados con cinta. El resultado eran clips visualmente impresionantes pero “tontos” — no entendían física, no respetaban continuidad entre frames, no recordaban contexto entre ediciones.
Omni colapsa esa separación. Es el mismo razonamiento que potencia Gemini 3.5 Flash, pero aplicado a generación visual. Eso se traduce en tres mejoras concretas:
- Física correcta: los objetos pesan, las pelotas rebotan, los líquidos fluyen, las telas se mueven con gravedad. No es perfecto pero es notoriamente mejor que cualquier modelo previo de Google y compite seriamente con Sora 2.
- Memoria de escena entre ediciones: si pedís “cambiá el color de la chaqueta del personaje a rojo” en un clip, Omni mantiene la identidad del personaje, el fondo, el ritmo de movimiento y la iluminación. Los modelos anteriores re-generaban todo y rompían continuidad.
- Reasoning sobre conocimiento del mundo: si pedís “explicame plegamiento de proteínas en estilo claymation”, Omni genera un clip que es técnicamente correcto (no inventa estructuras), no solo visualmente plausible. Esa pieza es lo que Google llama “intelligence + rendering”.
El nombre “Omni” señala la ambición declarada: el modelo está diseñado para crear cualquier output desde cualquier input. Hoy genera video. El roadmap incluye imágenes y audio nativos como output (sin fecha). En texto Google sigue separando Gemini (lectura) y Omni (creación) por ahora, pero arquitectónicamente nada impide que converjan en el siguiente ciclo.
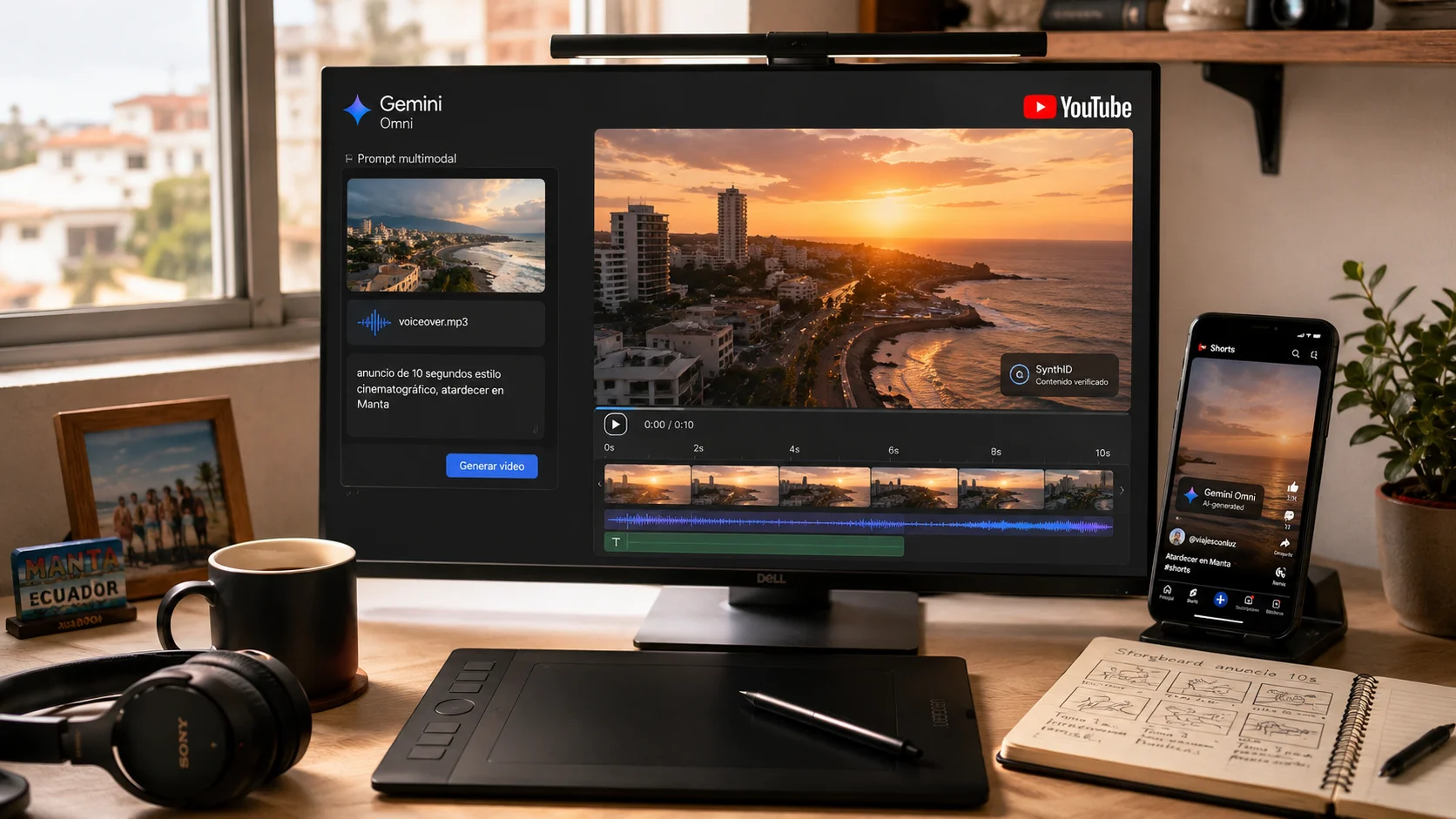
”Create anything from anything”: cómo funciona el input multimodal
La promesa de Omni es que aceptes cualquier combinación de modalidades en un solo prompt. En la práctica eso significa:
- “Tomá esta foto de mi gato + este clip de audio de él maullando + texto ‘corriendo por la sala con cámara lenta’ → video de 10 segundos”.
- “Tomá este video corto de un café + audio de una conversación + reemplazá a la persona con un avatar mío hablando en español ecuatoriano”.
- “Tomá estas 5 fotos del producto + descripción del catálogo + estilo del último anuncio que publiqué → video promocional de 10 segundos”.
A diferencia de pipelines anteriores que stitcheaban inputs por separado (imagen → control net → video → audio sobrepuesto), Omni razona sobre todos los inputs juntos y genera un solo output coherente. Esa diferencia se nota en la continuidad: el audio se sincroniza con el movimiento, la iluminación de la foto se respeta en la animación, el estilo del anuncio se aplica sin contradecir las fotos del producto.
Los modos que soporta hoy
| Input → Output | Disponible al lanzamiento |
|---|---|
| Texto → Video | Sí |
| Texto + imagen(es) → Video | Sí (hasta 5 imágenes de referencia) |
| Texto + video → Video editado | Sí |
| Texto + audio (voz) → Video con voz sincronizada | Sí, en preview regional |
| Texto + foto + audio → Avatar hablando | Sí, requiere onboarding del avatar |
| Imagen → Imagen editada | Pronto, mismo modelo |
| Texto → Audio narrado | Pronto, mismo modelo |
El modo más interesante para muchos creadores es avatar. Omni te permite grabar una sesión de onboarding (Google pide leer una serie de números en voz alta — un mecanismo anti-deepfake similar al de Sora 2) y a partir de ahí podés generar videos donde tu avatar aparece y habla. Solo el creador del avatar puede usarlo en su cuenta, lo que mitiga el uso para suplantación de identidad de terceros.
Lo que todavía no puede hacer
Google fue inusualmente transparente sobre las limitaciones. Vale la pena listarlas porque marcan el límite de lo que podés hacer hoy:
- Editar audio o voz dentro de un video existente no está disponible. Si subís un video con audio y le pedís a Omni que cambie lo que dice un personaje, no funciona — Google dejó esa capacidad fuera intencionalmente por riesgos de deepfake.
- Generar clips más largos de 10 segundos no es posible en Omni Flash. Google dice que es “una decisión de despliegue, no una limitación del modelo”, lo que implica que el modelo puede técnicamente generar más pero no expusieron ese control al usuario al lanzamiento.
- Generar contenido con personas identificables sin avatar autorizado está bloqueado por filtros de safety. No vas a poder generar a una celebridad ni a un político en un video.
- Audio en lenguaje natural distinto al inglés está en preview limitado. Para voz en español neutro funciona, pero para acentos regionales (ecuatoriano, colombiano, argentino) hay menos calidad. Esperá mejoras en el próximo ciclo.
- API pública no está disponible aún. Google la prometió “en las próximas semanas” para developers y empresas vía Vertex AI.
La omisión de edición de audio en video es la decisión política más interesante. Es exactamente la feature que más facilitaría deepfakes, y Google la dejó fuera explícitamente por riesgo reputacional. Es una decisión que probablemente cambien en 6-12 meses cuando tengan más confianza en los filtros — o cuando la presión competitiva los obligue.
Las demos que mostró Google en I/O 2026
La keynote del 19 de mayo incluyó cuatro demos concretas que vale la pena recordar porque definen el rango de uso esperado:
Demo 1: marble physics. Prompt: “una pelota de mármol rodando por un mostrador de cocina, golpeando una taza, haciendo sonar una campana”. El clip resultante tenía física correcta (rebote del mármol, sonido de la campana al impacto, sonidos secundarios coherentes con la materia de cada objeto). Lo importante no era el realismo visual sino que el modelo entendía las relaciones físicas entre los objetos.
Demo 2: claymation explainer de plegamiento de proteínas. Prompt: “un video estilo claymation explicando cómo se pliegan las proteínas, con narración en inglés”. El output fue un clip de stop-motion con narración voice-over que describía estructuras secundarias y terciarias técnicamente correctas. Pieza clave: Omni no inventó estructuras de proteínas; aplicó conocimiento real al render.
Demo 3: edición conversacional. Tomaron un clip generado previamente y le pidieron “cambiá el clima a noche lluviosa, mantené el personaje y el movimiento”. El resultado mantuvo identidad de personaje, ritmo y composición, ajustando solo iluminación, partículas de lluvia y reflejos. Ningún modelo previo de Google había hecho esto sin re-generar todo.
Demo 4: producto a anuncio. Pasaron 5 fotos de un producto + descripción de catálogo + prompt “anuncio de 10 segundos estilo Apple”. Omni armó un video con texto on-screen, transiciones, música sugerida y composición tipo TVC en menos de un minuto de generación. La calidad no compite con un anuncio profesional, pero como point of departure para iterar, es funcional.
Lo común entre las cuatro demos: Omni entiende intención, no solo descripción visual. Los prompts no decían “agregá lluvia con un opacity de 30% y bajá la luminosidad un 40%”. Decían “noche lluviosa”, y Omni resolvió los detalles.
Omni vs Veo 3.1: qué reemplaza y qué hereda
Hasta el 19 de mayo, el modelo de video generativo de Google era Veo 3.1, lanzado en el ciclo anterior. Omni lo reemplaza completamente en la app Gemini, en Flow y en YouTube. Veo 3.1 sigue accesible vía API legacy en Vertex AI para clientes que ya construyeron pipelines arriba, pero no recibe features nuevas.
Diferencias prácticas entre Omni Flash y Veo 3.1:
| Capacidad | Veo 3.1 | Gemini Omni Flash |
|---|---|---|
| Generación texto → video | Sí | Sí, con razonamiento mejorado |
| Inputs multimodales en un prompt | Limitado (texto + 1 imagen) | Texto + 5 imágenes + audio + video |
| Audio nativo en el clip | Sí (música, foley básico) | Sí, integrado con física de objetos |
| Edición conversacional | No | Sí, con memoria de escena |
| Avatar del usuario | No | Sí, con onboarding anti-deepfake |
| SynthID watermark | Sí | Sí, V2 más robusto |
| Duración máxima | 12 segundos | 10 segundos (Flash; Pro pronto) |
| Disponible en YouTube Shorts | No | Sí, gratis |
Omni hereda de Veo el stack de safety: SynthID watermark, filtros contra contenido violento o sexualizado, bloqueo de identidades públicas. La mejora en SynthID es V2: el watermark sobrevive a recompresión, escalado y screenshot, mientras que el V1 de Veo se podía romper con ciertas operaciones de post.
Para quien construyó workflows con Veo 3.1 vía Vertex AI, la migración a Omni vía API va a requerir cambios — los inputs son distintos (multimodales vs. mono), los outputs traen metadata extra para la edición conversacional, y los precios todavía no se publicaron. La estimación razonable, basada en la relación Flash/Pro en otros modelos de Gemini, es USD 0.05–0.10 por segundo generado para Omni Flash cuando llegue la API.
Distribución: app Gemini, Flow y YouTube Shorts gratis
La estrategia de distribución de Omni es la pieza más agresiva del anuncio y vale la pena entenderla porque señala intención.
App Gemini (todos los planes pagos): incluido en Google AI Plus (USD 20/mes), Pro (USD 30/mes) y Ultra (USD 100/mes). Es el surface principal para consumidores que ya pagan.
Flow (Google AI Plus y arriba): Flow es el editor creativo de Google que combina generación de imagen, video y audio. Omni reemplaza al backend de generación de video con razonamiento mejorado. Para creadores serios, Flow + Omni es probablemente el mejor combo end-to-end disponible hoy.
YouTube Shorts y YouTube Create app (gratis para todos): la decisión que cambia el mercado. Cualquier creador con cuenta de YouTube puede generar videos con Omni Flash sin pagar nada, siempre que el output viva en Shorts. Eso significa:
- Onboarding inmediato de millones de creadores que nunca pagaron por un modelo de IA.
- Compresión del mercado de creadores de Shorts en LatAm — Runway, Pika y Kling pierden razón de ser para este segmento porque Omni hace lo mismo gratis con integración nativa al feed.
- Riesgo de saturación de contenido AI en Shorts. YouTube probablemente va a introducir labeling más visible para distinguir contenido generativo de tradicional en los próximos meses.
La movida es clásica de Google: regalar capacidad cara en superficies que ya controlan (YouTube tiene 2.5B usuarios activos al mes) para sembrar el ecosistema, sabiendo que el largo plazo se monetiza por otro lado (suscripciones de Gemini para creadores avanzados, API para empresas, ads en Shorts mejorado por contenido nuevo).
El asterisco SynthID y la prevención de deepfakes
Cada video generado por Omni lleva SynthID V2, el watermark imperceptible de Google. SynthID V2 incrusta una firma cripto en el dominio de frecuencias del video que sobrevive a:
- Recompresión (H.264, H.265, VP9, AV1).
- Reescalado (downsampling hasta 360p, upscaling hasta 4K).
- Screenshot de frames individuales.
- Edición con crop hasta 30% del frame.
- Cambios de framerate (24→30→60 fps).
Lo que no sobrevive SynthID V2: recortes muy agresivos del video (más del 50%), filtros de estilo extremos, y conversión a otro medium (capturar el video con una cámara apuntando a la pantalla). Esos casos requieren detectores externos basados en patrones generativos visuales.
Google expuso una herramienta pública en la app Gemini, en Chrome y en Google Search para verificar si un video tiene SynthID. Eso es relevante porque a partir de mayo de 2026 cualquiera puede chequear si un clip viral fue generado por Omni — no por Sora, no por Kling, no por Veo legacy, específicamente por Omni. La cobertura de detección de otros generadores requiere los detectores que cada lab implementa por separado.
Para el ecosistema en LatAm la implicancia es práctica: los medios de comunicación pueden integrar verificación de SynthID en su pipeline editorial. Una nota que recibe un video sospechoso puede correr una verificación de 5 segundos antes de publicarlo. Esa pieza no resuelve deepfakes completos (un mal actor usa otro modelo) pero sí filtra los casos donde Omni es la fuente.
Comparación con Sora 2, Runway Gen-4 y Kling 2.0
Los cuatro competidores serios en video generativo a mayo de 2026.
| Métrica | Gemini Omni Flash | Sora 2 | Runway Gen-4 | Kling 2.0 |
|---|---|---|---|---|
| Duración por clip | 10 s | 20 s | 16 s | 15 s |
| Resolución máxima | 1080p | 1080p | 1080p | 720p estable, 1080p experimental |
| Audio integrado | Sí, físico-coherente | Sí, generativo separado | Sí, vía Runway Audio | Limitado |
| Edición conversacional | Sí, con memoria | Limitada | Sí, vía Runway Edit | No |
| Avatares de usuario | Sí, anti-deepfake | Sí, “cameos” | No nativo | No nativo |
| Costo base | Incluido en AI Plus / Pro / Ultra | USD 20/mes (Plus) | USD 15/mes (Standard) | USD 7/mes (Standard) |
| YouTube Shorts gratis | Sí | No | No | No |
| Watermark | SynthID V2 | C2PA + visible | Visible | Visible (en gratis) |
| API pública | Próximas semanas | Vía OpenAI API hoy | Sí, Runway API | Sí, Kuaishou API |
La lectura corta:
- Sora 2 sigue siendo el techo de calidad visual pura y la mejor duración por clip. Su debilidad es la falta de razonamiento físico al nivel de Omni y la dependencia de la suscripción separada de OpenAI.
- Runway Gen-4 es el más sólido en el flujo profesional (edición, masking, control fino, integración con DaVinci). Sigue siendo la elección de cineastas y agencias.
- Kling 2.0 gana en relación calidad-precio para mercados con presupuesto ajustado. Su debilidad es la falta de presencia en mercados occidentales y los términos de uso menos claros.
- Omni Flash gana en integración con el resto del stack Google (Workspace, YouTube, Gemini app), en costo (gratis en Shorts), y en razonamiento. Pierde en duración por clip.
Para un creador en Ecuador, el cálculo razonable hoy es: Omni Flash para Shorts y experimentación gratuita, Sora 2 si la calidad visual es prioridad y podés justificar el costo, Runway si trabajás en pipeline de producción serio, Kling como complemento barato para volumen.
Casos de uso para creadores en LatAm
Cinco casos donde Omni Flash ya es útil hoy desde Ecuador y la región:
- Anuncios cortos para PYMEs. Una panadería en Guayaquil puede subir 4 fotos de su producto + descripción + estilo “calidez familiar” y generar un Short de 10 segundos para Instagram Reels o TikTok. Costo: cero si se publica en YouTube Shorts.
- Explicadores educativos. Profesores de colegios secundarios y universidades pueden generar visualizaciones de conceptos (movimiento parabólico, estructuras químicas, eventos históricos). Omni respeta el conocimiento técnico mejor que cualquier modelo previo.
- Promociones de eventos locales. Festivales en Quito, eventos gastronómicos en Cuenca, ferias de tecnología — todos casos donde armar un teaser de 10 segundos era caro y ahora es trivial.
- Avatares para servicio al cliente en video. Para PYMEs que quieren responder consultas comunes en video sin grabarse, el avatar de Omni permite generar respuestas a la carta. Limitación importante: el avatar es propio del usuario, no genérico.
- Pruebas A/B de creatividades. Una agencia puede generar 5 variantes de un anuncio con un mismo prompt cambiando estilo, ritmo o foco, y testear cuál performa mejor antes de invertir en producción real.
Lo que no recomendamos hoy: contenido editorial de medios (riesgo de credibilidad), capturas legales o forenses (clips generados no son evidencia), y contenido para mercados muy regulados (salud, finanzas reguladas) donde la precisión de cada detalle es crítica.
Tabla resumen
| Pregunta | Respuesta corta |
|---|---|
| ¿Cuándo se lanzó Gemini Omni? | 19 de mayo de 2026 en Google I/O |
| ¿Modelo disponible? | Omni Flash (Pro pronto) |
| ¿Duración máxima por clip? | 10 segundos en Flash |
| ¿Inputs aceptados? | Texto, hasta 5 imágenes, audio, video |
| ¿Disponible gratis? | Sí, en YouTube Shorts y YouTube Create |
| ¿Reemplaza a Veo 3.1? | Sí, en app Gemini y Flow |
| ¿Watermark? | SynthID V2, verificable en Chrome y Search |
| ¿API pública? | ”Próximas semanas” vía Vertex AI |
Preguntas frecuentes
¿Gemini Omni es lo mismo que Veo 3.1 con otro nombre?
¿Puedo usar Gemini Omni desde Ecuador?
¿Cuánto cuesta usar Gemini Omni?
¿Por qué Omni no genera clips de más de 10 segundos si el modelo puede?
¿Cómo funciona el avatar y qué tan seguro es contra suplantación?
¿Puedo usar Omni para hacer doblajes o cambiar la voz de un video existente?
¿Cómo se compara la calidad visual de Omni con Sora 2?
¿Qué pasa si alguien usa Omni para crear contenido falso sobre mí?
Azirgo
¿Listo para construir tu Producto Digital?
Sitios web, apps móviles, software a medida y soluciones blockchain. Cuéntanos qué tienes en mente y armamos un plan claro contigo.
- Cotización clara en 48 horas
- Equipo en Ecuador, atención en español
- Desde un MVP hasta un producto en producción